Exploring Other Neural Network Architectures
3. Recurrent Neural Networks Part 2
Let’s dive a little bit deeper into how RNNs work.
As a quick refresher from the first lesson, unlike traditional feedforward neural networks that process inputs independently, RNNs introduce a temporal aspect by maintaining an internal state or “‘memory”. This memory enables RNNs to retain information from previous steps in a sequence, allowing them to recognize and distinguish context within a dataset.
How does it do this?
At the heart of RNNs lies a unique architecture that allows them to process sequential information. RNNs feature recurrent connections, forming a loop within the network. These connections enable the information to persist and be passed along, ensuring that the network considers the context of each element in a sequence. This memory mechanism allows RNNs to exhibit dynamic behavior, making them particularly well-suited for tasks where understanding the order and relationships between elements is critical.
Here is a nice illustration of this loop.
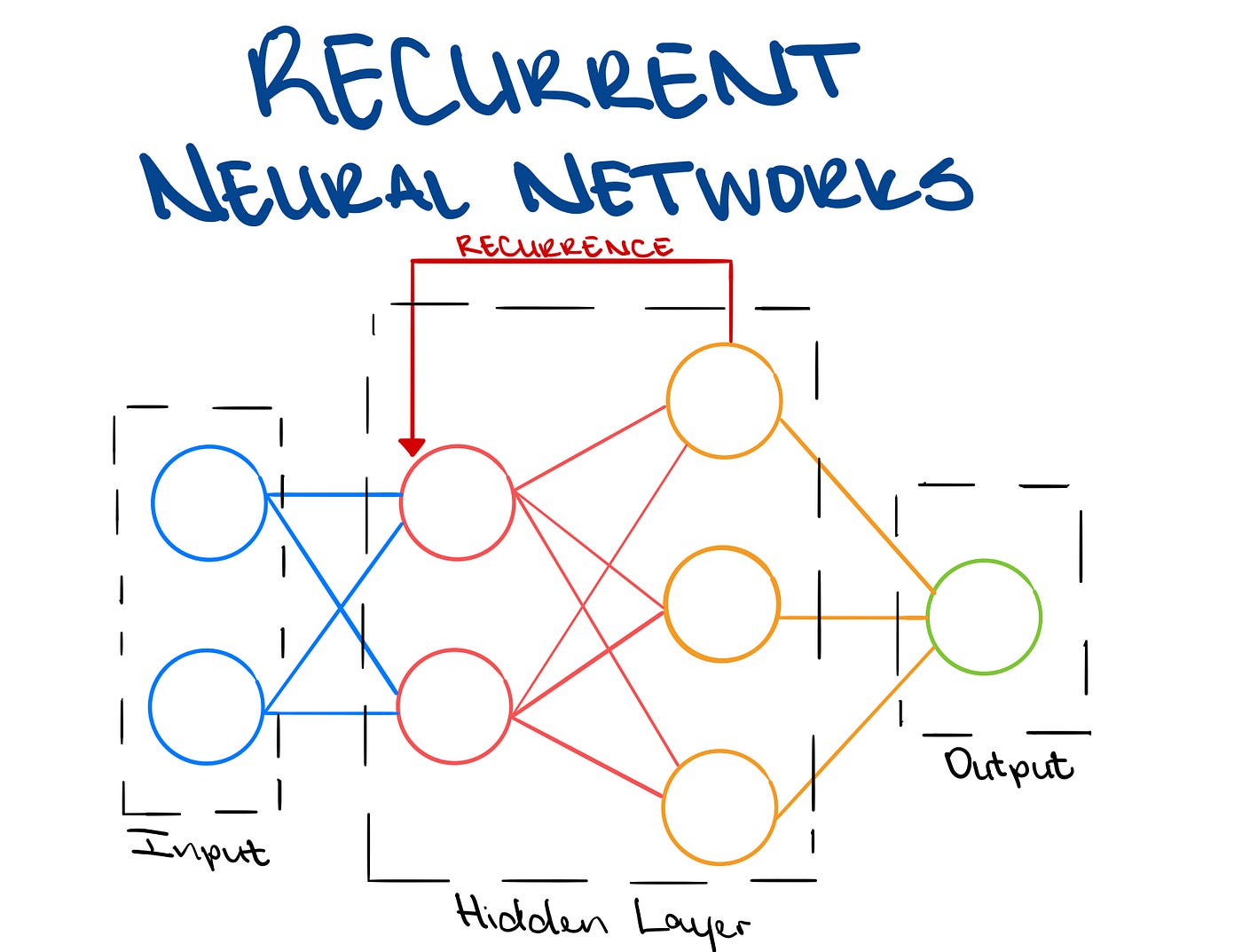
During the training phase, RNNs learn to adjust their parameters with backpropagation not only based on the current input but also on the information stored in their memory from previous steps.
This recursive learning process enables RNNs to adapt to patterns and dependencies within the data.
However, traditional RNNs face challenges like the vanishing gradient problem, where the influence of distant past information diminishes during training. To address this, advanced RNN architectures, such as Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs), have been developed.
Let’s explore LSTMs further.
LSTMs are one of the most commonly used RNN architectures, specifically designed to overcome challenges like the vanishing gradient problem (as mentioned previously). LSTMs introduce a sophisticated memory mechanism that enables them to capture long-term dependencies and temporal patterns within sequential data.
On of the most important aspects of LSTMs is the concept of a memory cell, which acts as a storage unit capable of retaining information for an extended duration.
LSTMs employ a set of gates—input gates, forget gates, and output gates—to regulate the flow of information within the memory cells. The input gate determines which information to store in the cell, the forget gate decides what information to discard, and the output gate controls the release of information from the cell. This intricate gating mechanism allows LSTMs to selectively retain and utilize information over varying time scales.
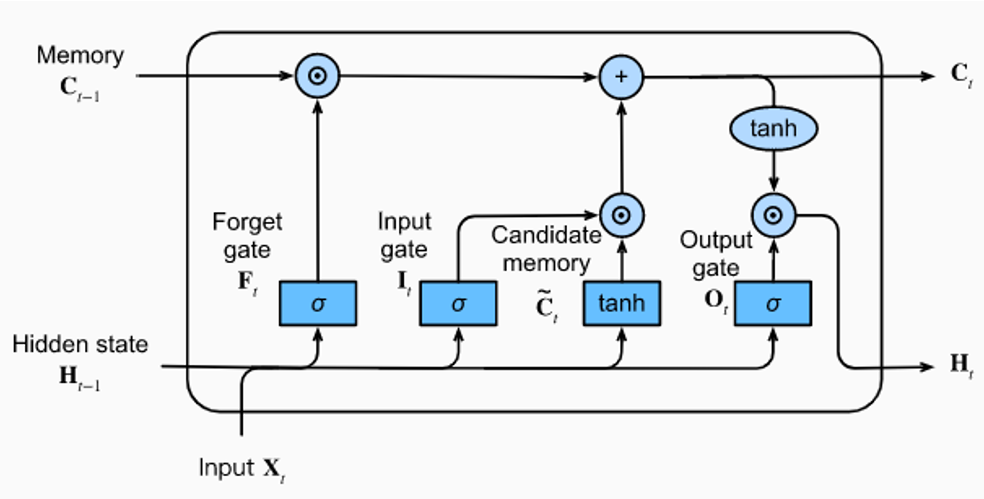
The gating mechanisms in LSTMs enable the network to decide when to update or forget information, preventing the vanishing gradient problem by allowing relevant information to persist throughout the learning process.
The intricate combination of gates and memory cells allows LSTMs to “remember”, “forget", and utilize information from different points in the sequence, making them proficient in handling diverse sequential data, such as natural language, time series, and audio signals.